How Function Execution Works
Where Functions Are Executed
You can execute data-independent functions or data-dependent functions in Geode in the following places:
For Data-independent Functions
- On a specific member or members—Execute the function within a peer-to-peer cluster, specifying the member or members where you want to run the function by using
FunctionServicemethodsonMember()andonMembers(). - On a specific server or set of servers—If you are connected to a cluster as a client, you can execute the function on a server or servers configured for a specific connection pool, or on a server or servers connected to a given cache using the default connection pool. For data-independent functions on client/server architectures, a client invokes
FunctionServicemethodsonServer()oronServers(). (See How Client/Server Connections Work for details regarding pool connections.) - On member groups or on a single member within each member group—You can organize members into logical member groups. (See Configuring and Running a Cluster for more information about using member groups.) You can invoke a data independent function on all members in a specified member group or member groups, or execute the function on only one member of each specified member group.
For Data-dependent Functions
- On a region—If you are executing a data-dependent function, specify a region and, optionally, a set of keys on which to run the function. The method
FunctionService.onRegion()directs a data-dependent function to execute on a specific region.
See the org.apache.geode.cache.execute.FunctionService Java API documentation for more details.
How Functions Are Executed
The following things occur when executing a function:
- For security-enabled clusters, prior to executing the function,
a check is made to see that that caller is authorized to execute
the function.
The required permissions for authorization are provided by
the function’s
Function.getRequiredPermissions()method. See Authorization of Function Execution for a discussion of this method. - Given successful authorization,
Geode invokes the function on all members where it
needs to run. The locations are determined by the
FunctionServiceon*method calls, region configuration, and any filters. - If the function has results, they are returned to the
addResultmethod call in aResultCollectorobject. - The originating member collects results using
ResultCollector.getResult.
Highly Available Functions
Generally, function execution errors are returned to the calling application. You can code for high availability for onRegion functions that return a result, so Geode automatically retries a function if it does not execute successfully. You must code and configure the function to be highly available, and the calling application must invoke the function using the results collector getResult method.
When a failure (such as an execution error or member crash while executing) occurs, the system responds by:
- Waiting for all calls to return
- Setting a boolean indicating a re-execution
- Calling the result collector’s
clearResultsmethod - Executing the function
For client regions, the system retries the execution according to org.apache.geode.cache.client.Pool retryAttempts. If the function fails to run every time, the final exception is returned to the getResult method.
The default number of retries is the total number of servers present. For member calls, if a function fails then the system will retry on each server only once or until no data remains in the system for the function to operate on. If the function fails on every server, then an exception will be returned to the user.
Function Execution Scenarios
This figure shows the sequence of events for a data-independent function invoked from a client on all available servers.
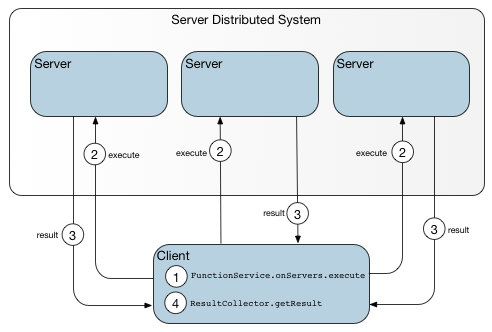
The client contacts a locator to obtain host and port identifiers for each server in the cluster and issues calls to each server. As the instigator of the calls, the client also receives the call results.
This figure shows the sequence of events for a data-independent function executed against members in a peer-to-peer cluster.
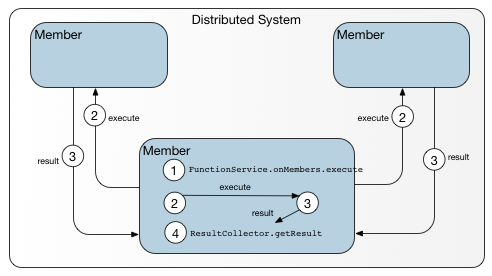
You can think of onMembers() as the peer-to-peer counterpart of a client-server call to onServers(). Because it is called from a peer of other members in the cluster, an onMembers() function invocation has access to detailed metadata and does not require the services of a locator. The caller invokes the function on itself, if appropriate, as well as other members in the cluster and collects the results of all of the function executions.
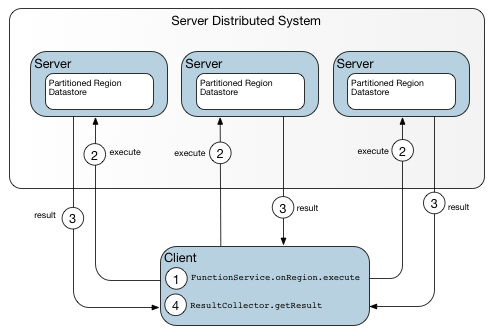
Data-dependent Function on a Region shows a data-dependent function run on a region.
Figure: Data-dependent Function on a Region
An onRegion() call requires more detailed metadata than a locator provides in its host:port identifier. This diagram shows the path followed when the client lacks detailed metadata regarding target locations, as on the first call or when previously obtained metadata is no longer up to date.
The first time a client invokes a function to be executed on a particular region of a cluster, the client’s knowledge of target locations is limited to the host and port information provided by the locator. Given only this limited information, the client sends its execution request to whichever server is next in line to be called according to the pool allocation algorithm. Because it is a participant in the cluster, that server has access to detailed metadata and can dispatch the function call to the appropriate target locations. When the server returns results to the client, it sets a flag indicating whether a request to a different server would have provided a more direct path to the intended target. To improve efficiency, the client requests a copy of the metadata. With additional details regarding the bucket layout for the region, the client can act as its own dispatcher on subsequent calls and identify multiple targets for itself, eliminating at least one hop.
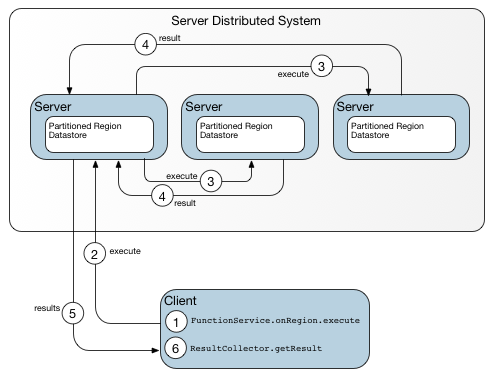
After it has obtained current metadata, the client can act as its own dispatcher on subsequent calls, identifying multiple targets for itself and eliminating one hop, as shown in Data-dependent function after obtaining current metadata.
Figure: Data-dependent function after obtaining current metadata
Data-dependent Function on a Region with Keys shows the same data-dependent function with the added specification of a set of keys on which to run.
Figure: Data-dependent Function on a Region with Keys
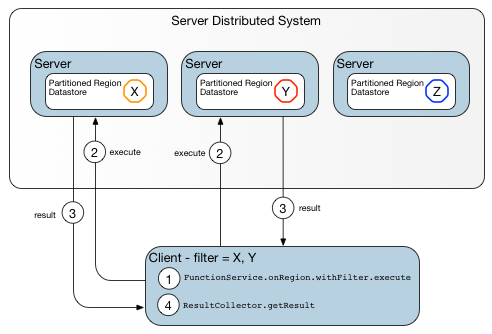
Servers that do not hold any keys are left out of the function execution.
Peer-to-peer Data-dependent Function shows a peer-to-peer data-dependent call.
Figure: Peer-to-peer Data-dependent Function
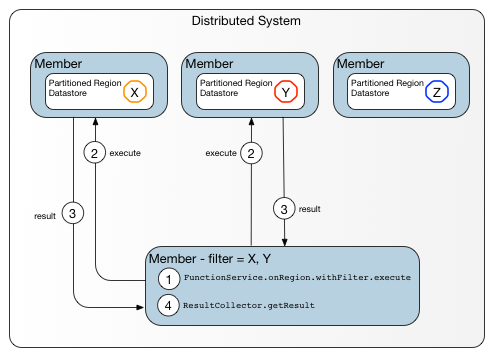
The caller is a member of the cluster, not an external client, so the function runs in the caller’s cluster. Note the similarities between this diagram and the preceding figure (Data-dependent Function on a Region with Keys), which shows a client-server model where the client has up-to-date metadata regarding target locations within the cluster.
Client-server system with Up-to-date Target Metadata demonstrates a sequence of steps in a call to a highly available function in a client-server system in which the client has up-to-date metadata regarding target locations.
Figure: Client-server system with Up-to-date Target Metadata
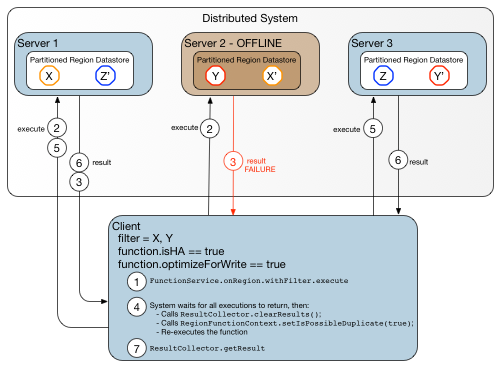
In this example, three primary keys (X, Y, Z) and their secondary copies (X’, Y’, Z’) are distributed among three servers. Because optimizeForWrite is true, the system first attempts to invoke the function where the primary keys reside: Server 1 and Server 2. Suppose, however, that Server 2 is off-line for some reason, so the call targeted for key Y fails. Because isHA is set to true, the call is retried on Server 1 (which succeeded the first time, so likely will do so again) and Server 3, where key Y’ resides. This time, the function call returns successfully. Calls to highly available functions retry until they obtain a successful result or they reach a retry limit.